Kubernetes experience with KOPS on AWS. February 2017


Intro
I was researching Kubernetes to use it on AWS recently. And I had mixed experience, which I want to share with you. In a hope that it will be useful for you.
For the lazy readers, the most useful part of this article is "Main reasons to say no to Kubernetes on AWS in February 2017"
Versions used:
Short story
The first application setup was really quick and smooth. The application running both on AWS and locally on minikube without any issues was impressive.
Later did setup the official monitoring and logging addons, did integrate CI for continuous delivery and the whole team was happy for several weeks.
And the after several weeks of trying to break Kubernetes in various ways, and getting more complex configurations into it, the problems began to appear.
Main problems, were about provisioning complexity. Something is provisioned by KOPS using Terraform. All other infrastructure is provisioned AWS Cloudformation. It spawned lots of problems for consistent environment provisioning. Kubernetes reassessment session was kicked off, after which all developments on Kubernetes were suspended.
The findings which were found noticeably positive and negative are shared in this blog post below.
Deployment architecture on AWS
There too many options to install Kubernetes on AWS. It is very distributed on the approaches available. The right and newest approach which is recommended by Kubernetes is to use Kubernetes KOPS. So I will focus on this approach only.
The other ways to set it up which are not recommended:
- Using the guide from CoreOS. https://coreos.com/kubernetes/docs/latest/ It is using AWS CloudFormation for provisioning.
- It is possible just to generate the template locally and then manually apply it.
- Old
kube-aws.shwhich is executed on one of the instances to setup K8S. Recently this approach was deprecated.
Kubernetes infrastructure
Under the hood of running cluster created by Kubernetes KOPS
- Created Dedicated VPC
- 1-3 autoscaling groups for Kubernetes master nodes. It is each per availability zone
- 1 autoscaling group for the worker nodes.
- IAMRole, IAMInstanceProfile for master and worker nodes
- Default security group
- Other VPC related stuff
The smallest recommended size for the nodes is m3.medium. Smaller instances are not recommended for production environment due to CPU throttling and running out of memory on t2 instances.
In prior versions of Kubernetes, we defaulted the master node to a t2-class instance, but found that this sometimes gave hard-to-diagnose problems when the master ran out of memory or CPU credits. If you are running a test cluster and want to save money, you can specify export MASTER_SIZE=t2.micro but if your master pauses do check the CPU credits in the AWS console. For production usage, we recommend at least
export MASTER_SIZE=m3.mediumandexport NODE_SIZE=m3.medium. And once you get above a handful of nodes, be aware that one m3.large instance has more storage than two m3.medium instances, for the same price.
Autoscaling
Kubernetes has different autoscaling ways:
- Horizontal Pod autoscaling. When certain CPU threshold is reached.
- Cluster scaling.
- On new container creation when it is not enough CPU and memory to allocate the Workers AWS ASG is scaled up.
- Cluster Manager is constantly checking if there is a way to reduce the number of instances.
- Custom Autoscaling alerts can be added on workers AWS ASG for upscale.
During upscale K8S with KOPS upscale scripts are installed on the node. It is based on OS without it. I believe no such installations should be done during upscale, because of simply when autoscaling happens, the new instance is already needed ASAP.
For the master, for clusters of
- Less than 5 nodes it will use an m3.medium,
- for 6-10 nodes it will use an m3.large;
- for 11-100 nodes it will use an m3.xlarge
- No more than 2000 nodes
- No more than 60000 total pods
- No more than 120000 total containers
- No more than 100 pods per node
Something to take it into account when you considering the costs.
Application deployment
Rolling update deployment is default deployment with rollback support.
Supported scripted BlueGreen deployment - the manual script.
In short, many deployment strategies are possible, but it needs to be scripted.
Logging and Monitoring
Kubernetes has official addons. It supports ELK stack for logging and various variations for cluster monitoring.
It works, kinda. These applications do not have persistence by default. If the containers will restart all collected data will be lost.
For persistently functioning solution, you will need to modify application .yaml and map volume blocks.
Confusing documentation
Very confusing explanation between different Kubernetes elements. For example between Replication controller and ReplicaSet. Until I've learned, that ReplicaSet is the new way to define the application it was completely not clear why there are 2 similar elements.
Another confusion is with how it is the best way to provision Kubernetes on AWS. There are so many ways, and while navigating through the documentation, you can find completely different ways install Kubernetes. And there is no deprecated label. Very confusing.
Great command line tool
This is the perfect example of top notch quality command line tool. The usage of command parameters is predictive and makes the command line usage comfortable.
I will provide couple examples from the kubectl cheatsheet:
kubectl attach my-pod -i # Attach to Running Container kubectl port-forward my-pod 5000:6000 # Forward port 6000 of Pod to your to 5000 on your local machine kubectl port-forward my-svc 6000 # Forward port to service kubectl exec my-pod -- ls / # Run command in existing pod (1 container case) kubectl exec my-pod -c my-container -- ls / # Run command in existing pod (multi-container case) kubectl top pod POD_NAME --containers # Show metrics for a given pod and its containers
These create very high intimacy with running containers. Which makes it easy to debug and develop. Of course, this is not something you should do in production. I just wanted to share the ease of usage.
Good dashboard
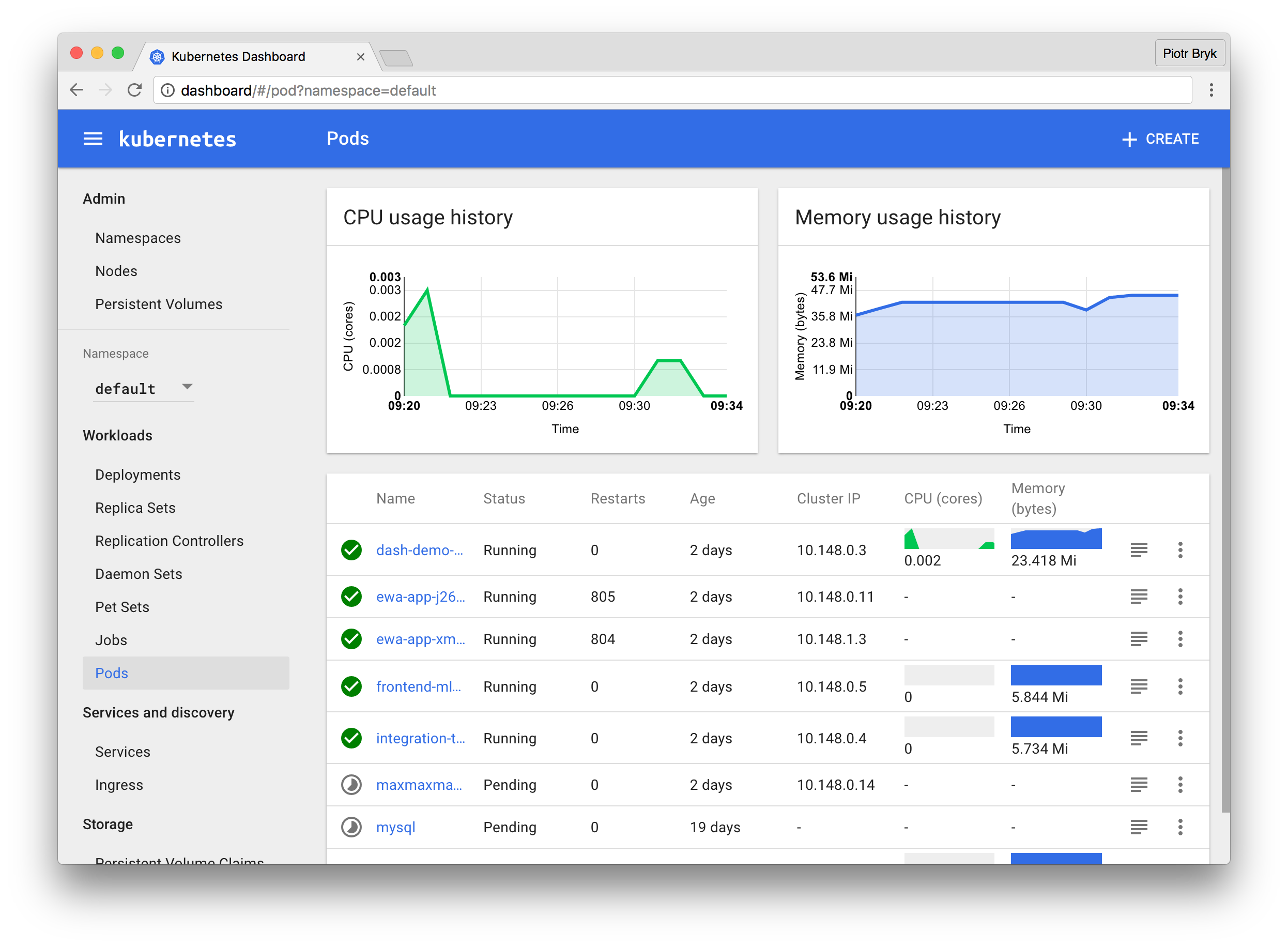
The dashboard is very positive experience.
- Additionally, with Heapster addon use can see primitive metrics.
- You can visually get the representation of almost all Kubernetes elements in the dashboard. Very useful when debugging and/or monitoring
- For a single container, it is possible to launch, edit and kill it from dashboard only without touching the code.
- Change the autoscaling policies
- Other small actions...
It helps in the situations to change or check something, and there is no need to check code or CLI.
Main reasons to say no to Kubernetes on AWS in February 2017
Kubernetes KOPS provisions its own VPC. Creates unneeded complexity on provisioning topic. KOPS automated provisioning will always conflict with custom provisioning using Terraform or especially AWS CloudFormation .
Does not support ALB.
Supports only HTTP 1.1 natively
No native integration of Kubernetes Ingress with AWS
Huge set of features is in alpha/beta state. These are not recommended to be used in production by Kubernetes development community. Source: Kubernetes Github issues and Kubernetes Slack.
Kubernetes KOPS tool is unstable and at any point randomly throws exceptions to the console. Really cannot explain the errors which happen in 6 out of 10 runs.
Because of often failing KOPS tool, cluster upgrades can be unpredictable. I only did upgrade several times, KOPS tool was randomly failing, but the upgrades were successful. But still, the experience is far from production grade.
Timeline of features getting to Kubernetes on AWS
After each Kubernetes release, there will be 30-60 days, until KOPS tool will be compatible with new version. The release cycle is relatively quick. Some feature will be already stable on google cloud at least for a month, and on AWS it won't be available.
Wishlist for Kubernetes on AWS
- make KOPS stable
- make KOPS provides persistent logging and monitoring add-ons out of the box
- create only one ASG for Kubernetes masters.
- terminate SSL at ELB in order to leverage existing SSL infrastructure with including ACM.
- support AWS IAM for containers like kube2iam.
- Route53 DNS integration like Mate does.
- And of course, CloudFormation is on a wishlist.
This is actually close to Zalando's vision.
General recommendations
- Use Kubernetes AWS when you need more than 5 worker nodes to run in production. The reasoning is the pricing. With high availability you will need at least 2-3 masters
m3.medium, and if you will have only 1-2 workers it will be inefficient. - Do not use Kubernetes on AWS if you need HTTP 2.0 support.
- Do not run on Kubernetes storage-based applications. It is working, but still buggy. There are high hopes that this topic would be stable in Kubernetes
1.6.0 - Do not use existing VPS for Kubernetes, because it will still modify it. In my case it wanted to rename the VPC.
- Do you plan to change VPC and ASG settings? They will go away after each KOPS run on cluster
- if yes, then continue only if you have dedicated sysop on the topic and time to research the strategy on provisioning consistency.
Thoughts on AWS
Undoubtedly Kubernetes is the top notch cluster, but it has issues with comfortably on AWS. AWS forces to use its own tools by providing all the internal integrations out of the box.
This way other options like Google Cloud and Kubernetes are left behind by the companies, which are focusing the development on AWS only.
So, the question is - Should we stop evaluating other than AWS products when running on AWS?
Thanks
That's it, thanks for reading. If you like please share it.